 进程创建
进程创建
# 进程创建
# 1、fork 进程创建
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成 进程树结构模型。
- #include <sys/type.h>
- #include <unistd.h>
- pid_t fork(void);
- 返回值:
- 成功:子进程中返回 0,父进程中返回子进程 ID
- 失败:返回 -1
- 失败的两个主要原因:
- 当前系统的进程数已经达到了系统规定的上限,这时 errno 的值被设置 为 EAGAIN
- 系统内存不足,这时 errno 的值被设置为 ENOMEM
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
//函数的作用:用于创建子进程。
返回值:
fork()的返回值会返回两次。一次是在父进程中,一次是在子进程中。
在父进程中返回创建的子进程的ID,
在子进程中返回0
如何区分父子进程和子进程:通过fork的返回值。
在父进程中返回 -1,表示创建子进程失败,并且设置 errno
2
3
4
5
6
7
8
9
10
//fork.c
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
// 创建子进程
pid_t pid = fork();
// 判断,判断是父进程还是子进程
if (pid > 0)
{
printf("pid : %d\n", pid);
// 如果大于0,返回的是创建的子进程的进程号
printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());
}
else if (pid == 0)
{
// 当前是子进程
printf("i am child process, pid : %d, ppid : %d\n", getpid(), getppid());
}
// for循环
for (int i = 0; i < 3; i++)
{
printf("i : %d, pid : %d\n", i, getpid());
sleep(1);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
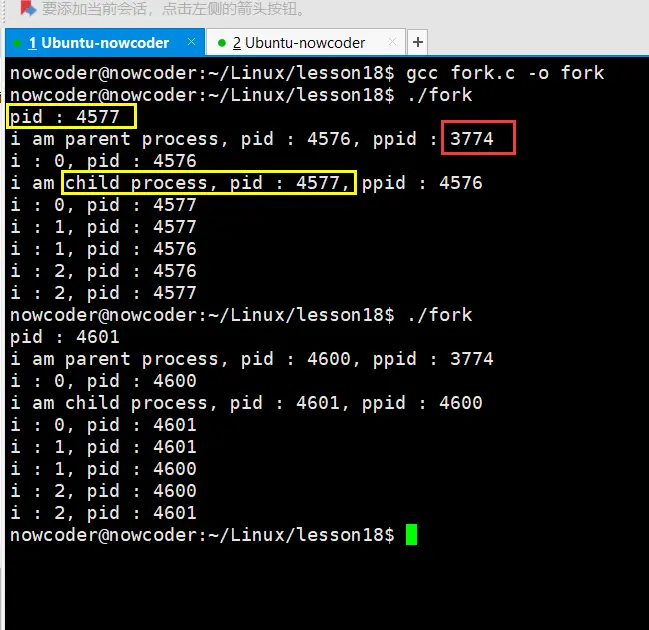
- 上图可以看出,fork函数成功执行,那么返回给父进程的就子进程的id
- 同时返回给子进程的值为 0
- 除此之外,我们还可以从for循环的执行顺序看出,(父子)进程是交替执行的
- 注意:父进程的父进程id ,我们使用
ps aux查看就会发现是 当前终端的 id,所以说终端也是进程
# 2、父子进程虚拟地址空间
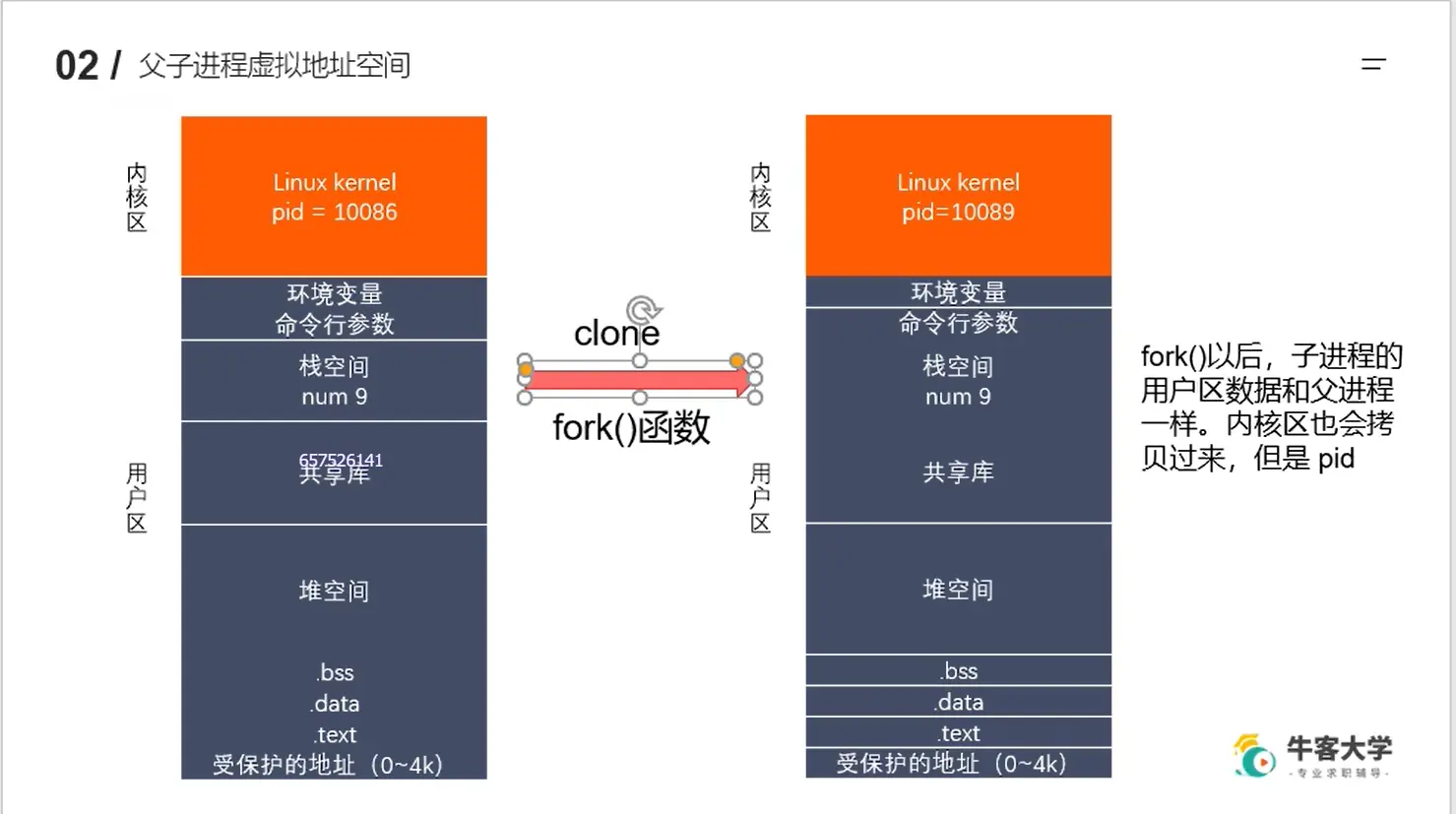
- 我们在使用fork() 函数创建子进程后,会克隆父进程的虚拟地址空间的内容给子进程,但是父子进程存放在内核区的进程id不同(子进程与父进程运行在分别的内存空间,在fork调用后,两者的内存空间有相同的内容)
- 因为子进程是拷贝了父进程的虚拟地址空间,所以它们保存在代码段(.text)里的代码也是完全相同的,之所以会执行不同的代码,是因为 fork() 函数给在父进程和子进程的返回值不同(上面
fork.c代码里,会发现我们定义了变量 pid 来存放fork的返回值,这个pid是局部变量,存放在栈空间里,不要把其误认为是存放在内核区里的进程id(pid)),所以才会有区别,这也是上面fork.c文件里的父子进程都会执行for循环的原因 - 如果父进程中有局部变量(存放在虚拟地址空间的栈空间里)num =9 ,然后我们创建子进程,再在父进程里对num进行操作,这样是不会对子进程的 num 造成影响的,因为他们的内存空间是不同的,只是内容相同而已,所以两者的num互不关联(下面例子就说明了这一点)
//fork.c
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
int num = 10;
// 创建子进程
pid_t pid = fork();
// 判断,判断是父进程还是子进程
if (pid > 0)
{
// printf("pid : %d\n", pid);
// 如果大于0,返回的是创建的子进程的进程号
printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());
printf("parent num : %d\n", num);
num += 10;
printf("parent num += 10: %d\n", num);
}
else if (pid == 0)
{
// 当前是子进程
printf("i am child process, pid : %d, ppid : %d\n", getpid(), getppid());
printf("child num : %d\n", num);
num += 100;
printf("child num += 100: %d\n", num);
}
// for循环
for (int i = 0; i < 3; i++)
{
printf("i : %d, pid : %d\n", i, getpid());
sleep(1);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
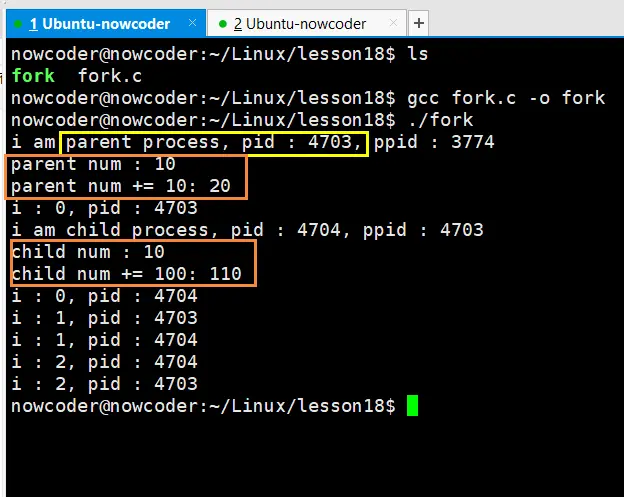
# 3、fork 写时拷贝
- 实际上,更准确来说,Linux的fork()使用是通过写时拷贝(copy-on-wite)实现。写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址空间,从而使各个进程拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。
- 注意: fork之后父子进程共享文件,fork产生的子进程与父进程相同的文件文件描述符指向相同的文件表,引用计数增加,共享文件偏移指针。
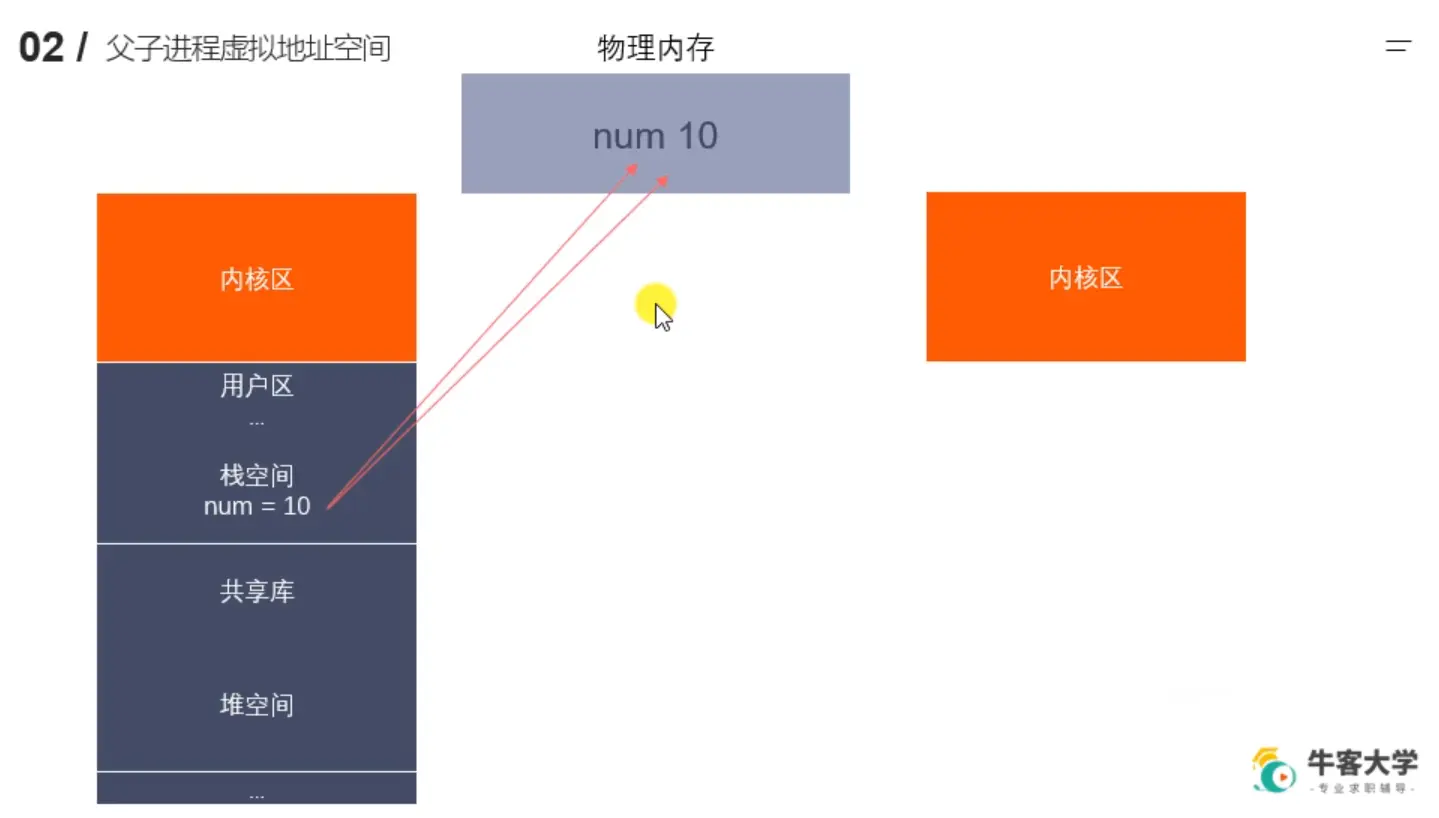
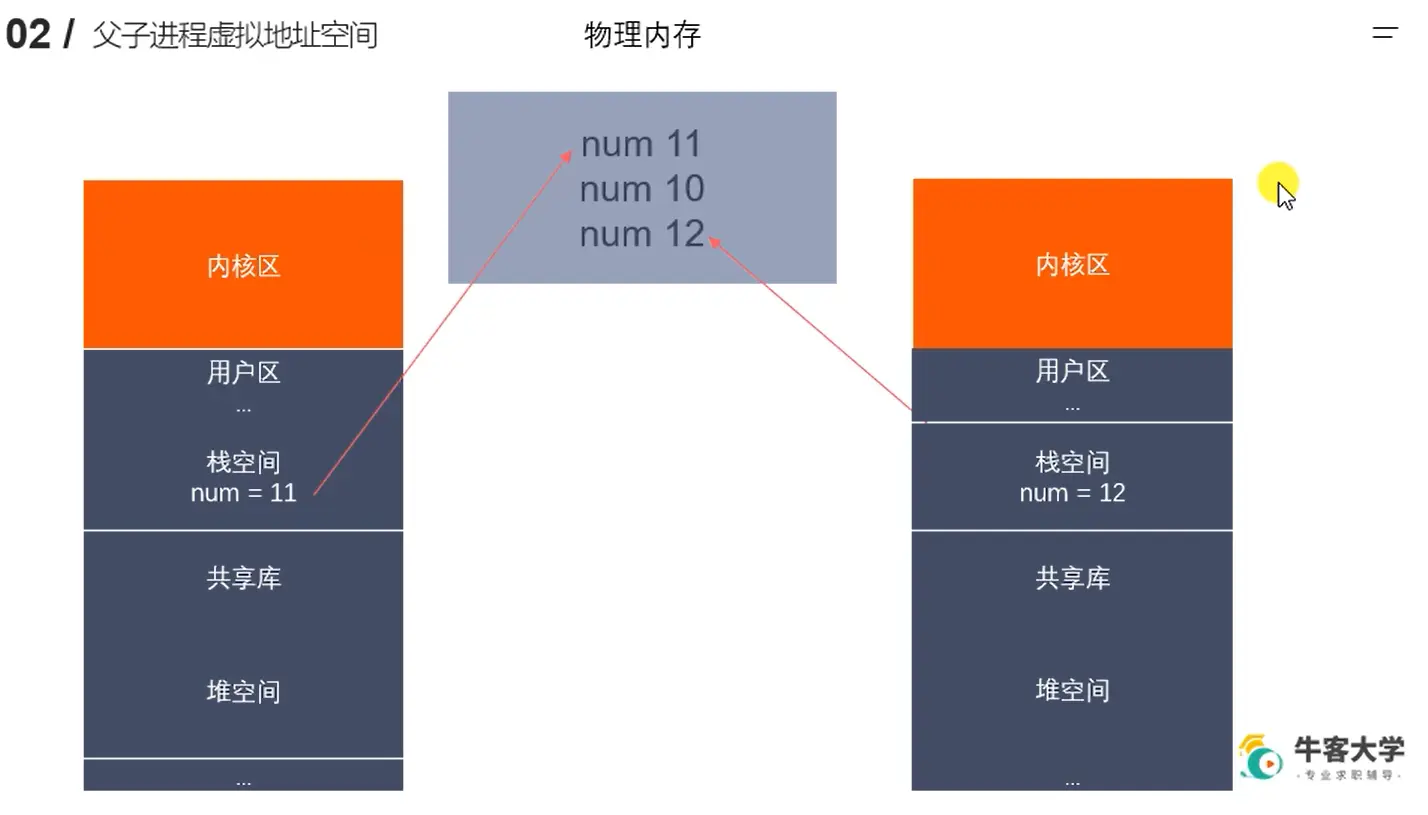
- 假设我们一开始只是读,然后有局部变量 num =10,那此时父子进程共享一个地址空间,都是用父进程的地址空间栈里的num映射去到物理内存里去获取真实的num值。
- 如果我们父进程要将num 改为11,那么会在真实的物理内存里开辟一个新的空间,存入num = 11,
- 子进程要将 num改为12,那么会在真实的物理内存里开辟一个新的空间,存入num = 12
# 4、虚拟地址思考
# 问题1:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(){
//为什么进程中的num地址是一样的呢?
int num = 10;
printf("original num: %d\n", num);
//输出原地址
printf("Address of original num: %p\n", &num);
pid_t pid = fork();
if (pid > 0){
printf("Parent process, PID = %d\n", getpid());
num += 1;
printf("num+1 in parent process: %d\n", num);
//输出父进程中num的地址
printf("Address of num in parent precess: %p\n", &num);
}
if (pid == 0){
printf("Child process, PID = %d\n", getpid());
num += 2;
printf("num+2 in child process: %d\n", num);
//输出子进程中num的地址
printf("Address of num in child precess: %p\n", &num);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
上面代码执行结果如下:
original num: 10 Address of original num: 0x7fffffffe200 Child process, PID = 5498 num+2 in child process: 12 Address of num in child precess: 0x7fffffffe200 Parent process, PID = 5493 num+1 in parent process: 11 Address of num in parent precess: 0x7fffffffe2001
2
3
4
5
6
7
8- 输出结果中父子进程地址一样,为什么呢?
原因是:这个是虚拟地址空间,不是实际的物理地址。
我们程序中使用的是虚拟地址空间(0-4G),每一个进程都有一个虚拟地址空间。因为是复制父进程的虚拟地址空间,用户段的数据都是一样的,所以对应的虚拟地址空间的位置也是一样的。 ,但是num所映射的物理地址是不一样的。1
# 问题2:
1.如果父进程的a变量改变了,是不是只会把子进程的a变量进行地址空间的复制,而用户区的其他变量都不会改变?2.内核区的数据是不是在子进程创建的时候就拷贝了,而不是遵循的写时拷贝的原则?
1.写时复制,在底层会重新在真实物理内存中创建一个空间保存数据,然后子进程中的虚拟地址映射到新的物理内存。2.内核区的数据一般用户是修改不了的,除非通过系统调用去修改才可以,内核区的数据应该也是遵循写时拷贝的原则的。
# 问题3:
# 5、fork总结
首先父进程执行到fork时会创建子进程,fork后会给父子进程分别返回一个pid号(父进程fork后返回的pid号为子进程的pid=10089,而返回给子进程的pid号为0。注意,该代码第二行的pid是由fork创建后返回的pid,并不是该进程本身的pid,这点容易搞混,最好改一下命名如r_pid好一些),此时系统会将父进程的用户去数据和内核区拷贝过来生成一段新的虚拟地址空间供子进程使用,然后父进程开始继续执行if()判断,此时子进程是在父进程fork()后创造出来的,因此子进程只会执行fork()之后的语句,即也进行if()判断。但不同的是父进程是通过栈空间返回的pid号为大于0的值,而子进程通过栈空间返回的pid号为等于0的值。因此父子进程执行的if条件语句并不相同。
(实际更精准的说,Linux的fork()函数是通过写时拷贝来实现的,即fork后内核实际并不复制整个父进程的地址空间,而是让父子进程以只读的方式共享一个地址空间,只有在写入操作时才会进行资源的复制操作)
//父子进程之间的关系:
区别:
1.fork()函数的返回值不同
父进程中:>0 返回的子进程的 ID
子进程中:=0
2.pcb中的一些数据
当前的进程的id pid
当前的进程的父进程的id ppid
信号集
共同点:
某些状态下,子进程刚被创建出来,还没有执行任何的写数据的操作
- 用户区的数据
- 文件描述符表
父子进程对变量是不是共享的?
- 刚开始的时候,是一样的,共享的。如果修改了数据,就不共享了。
- 读时共享(子进程被创建,两个进程没有做任何的写的操作),写时拷贝
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 6、GDB多进程调试
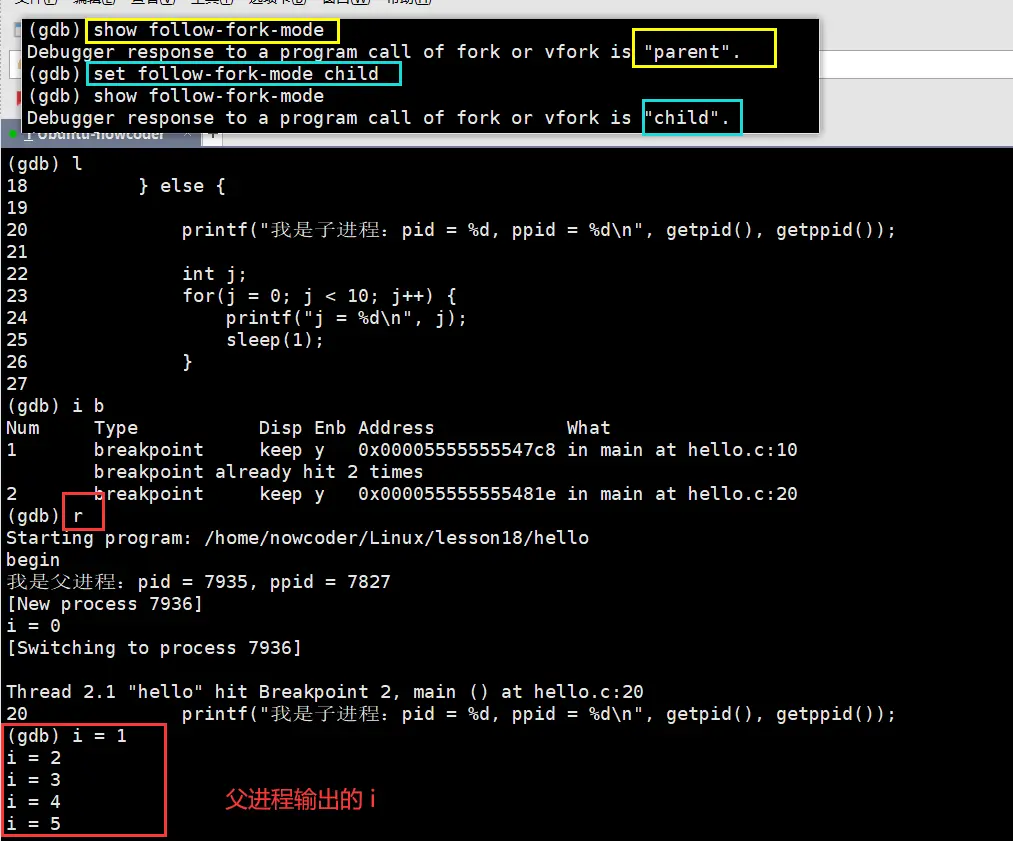
- 使用 GDB 调试的时候,GDB 默认只能跟踪一个进程,可以在 fork 函数调用之前,通过指令设置 GDB 调试工具跟踪父进程或者是跟踪子进程,默认跟踪父进程。
- 设置调试父进程或者子进程:
set follow-fork-mode [parent(默认)| child] - 设置调试模式:
set detach-on-fork [on | off]默认为 on,表示调试当前进程的时候,其它的进程继续运行,如果为 off,调试当前进程的时候,其它进程被 GDB 挂起。 - 查看调试的进程:
info inferiors - 切换当前调试的进程:
inferior id - 使进程脱离 GDB 调试:
detach inferiors id
//测试代码(hello.c)
#include <stdio.h>
#include <unistd.h>
int main() {
printf("begin\n");
if(fork() > 0) {
printf("我是父进程:pid = %d, ppid = %d\n", getpid(), getppid());
int i;
for(i = 0; i < 10; i++) {
printf("i = %d\n", i);
sleep(1);
}
}
//这里我们默认fork()不会出错,所以就直接使用 else
else {
printf("我是子进程:pid = %d, ppid = %d\n", getpid(), getppid());
int j;
for(j = 0; j < 10; j++) {
printf("j = %d\n", j);
sleep(1);
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
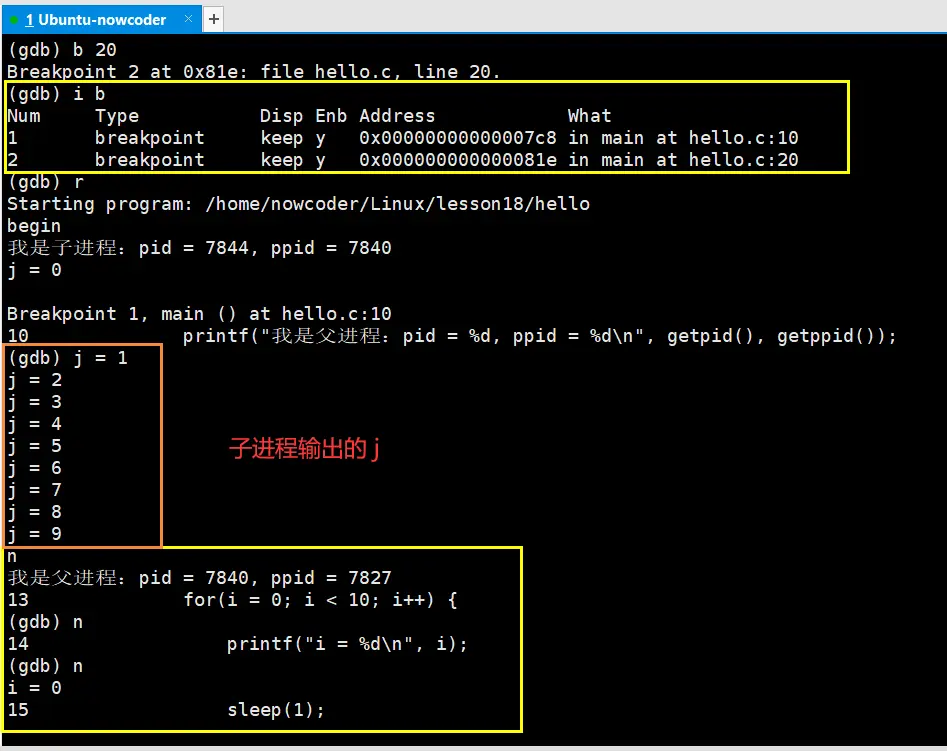
- 可以看出,GDB默认是调试的父进程,子进程会执行
# 6.1 设置调试的进程
- 查看:
show follow-fork-mode
- 设置:
set follow-fork-mode (父子进程)
# 6.2 设置调试模式
这里我们gcc 8以上的版本好像使用不了 set dethch-on-fork off 命令,所以这里没自己写,是直接在视频里截的图做的笔记
set dethch-on-fork off设置调试当前进程的时候,其它进程被 GDB 挂起
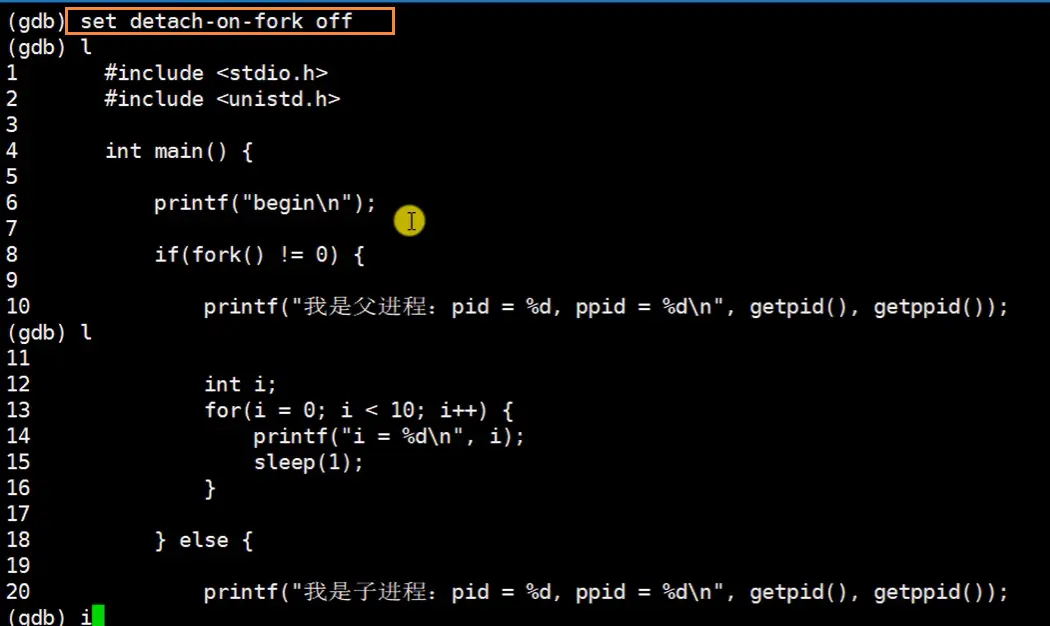
- 这里已经打了两个断点
b 10和b20 - 使用
info inferiors查看进程信息 - 使用
inferior 进程编号(Num),切换进程 - 注意:切换完进程后,不要直接 gcc 输入
n到下一行,要用c/continue跳到下一个断点(因为我们切换调试的进程了)
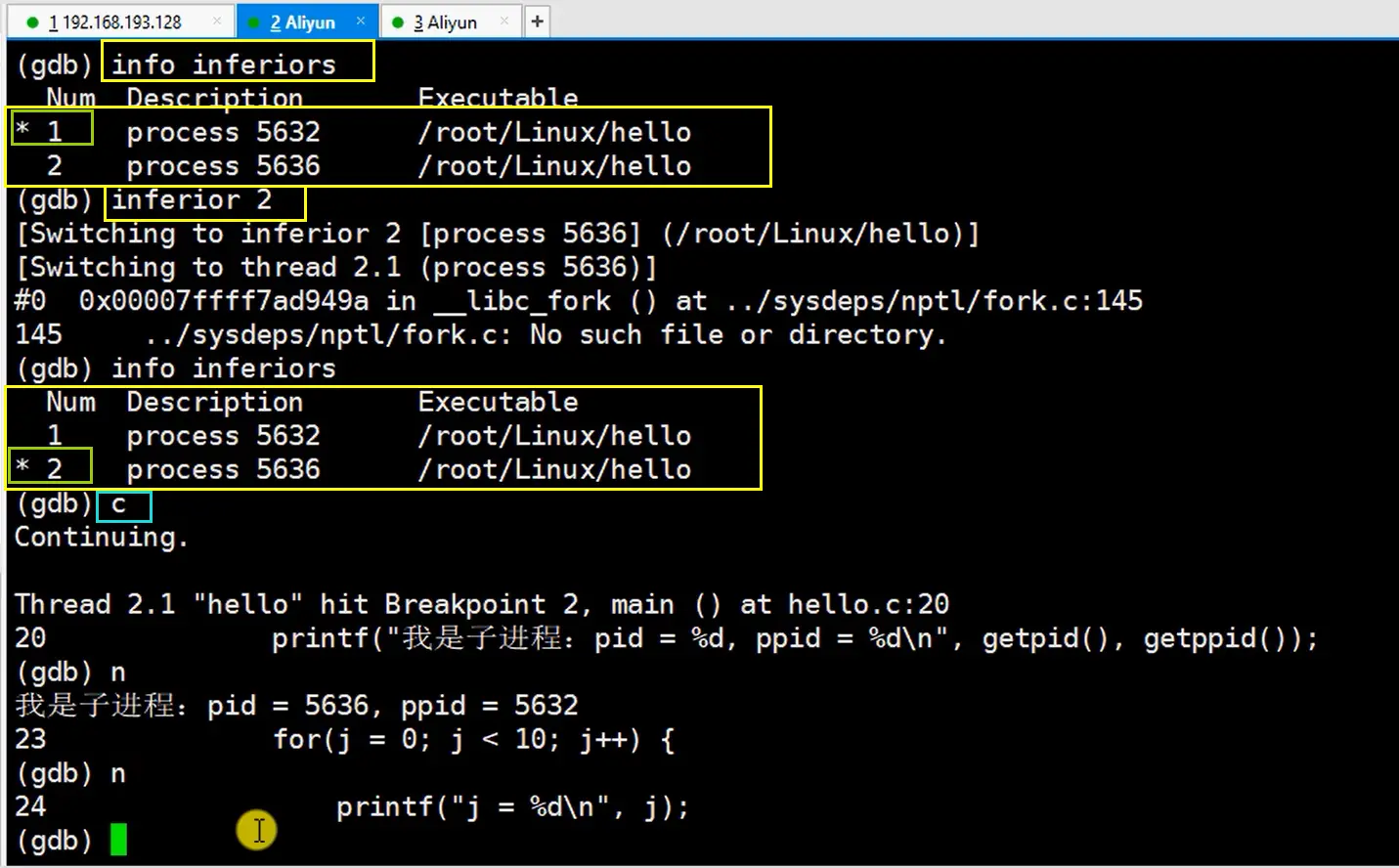
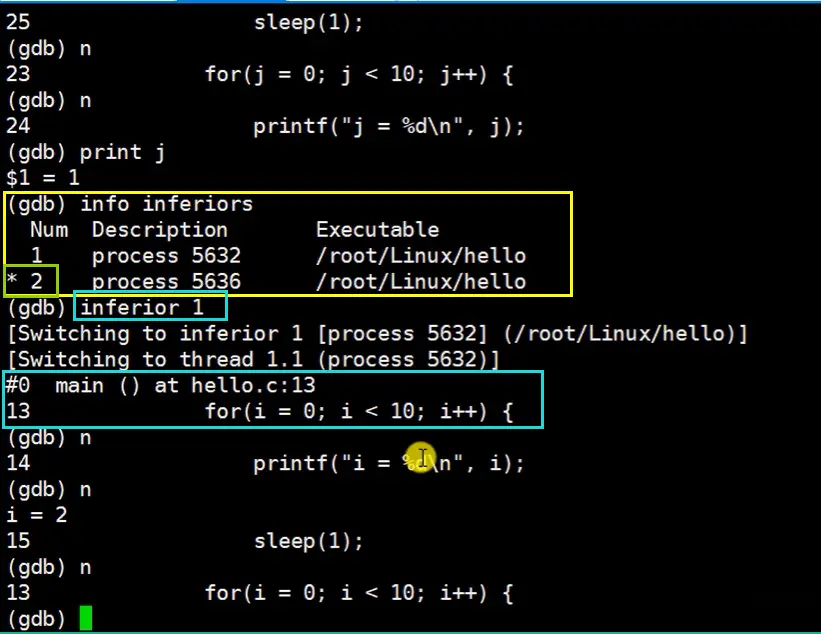
- 再切换会父进程,不会重新开始,而是回到上次切换进程时离开的点
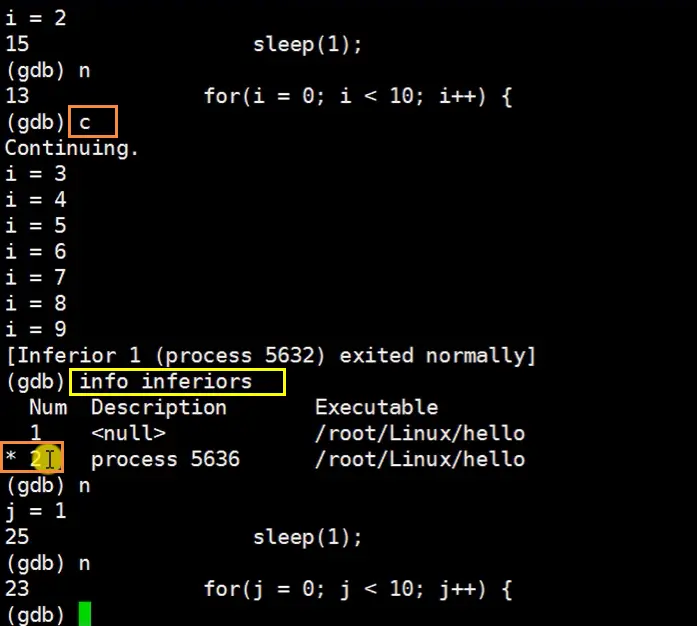
- 设置
set dethch-on-fork off后,如果一个进程调试结束,就会自动进入到另一个进程里
# 6.3 进程脱离 GDB 调试
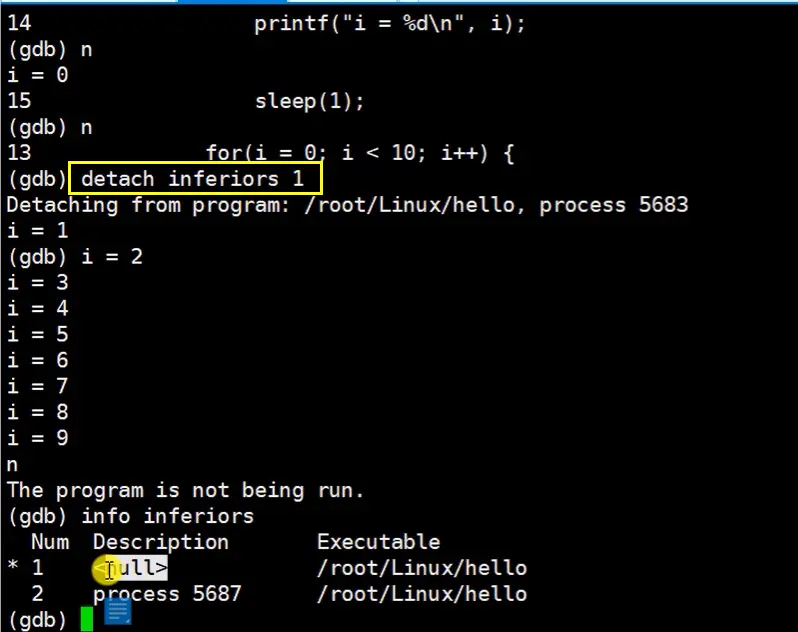
detach inferiors id
- 这里我们是先执行了
set detach-on-fork off指令 - 可以看出,我们使用
detach inferiors id命令后,当前进程就脱离了 GDB调试,自动执行到结束 - 如果我们要调试其他进程 ,就要执行
inferior 进程编号(Num),切换进程
# 7、exec() 族
# 7.1 exec 函数族介绍
- exec 函数族的作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,换句话说,就是在调用进程内部执行一个可执行文件。
- exec 函数族的函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据 段和堆栈等都已经被新的内容取代,只留下进程 ID 等一些表面上的信息仍保持原样, 颇有些神似“三十六计”中的“金蝉脱壳”。看上去还是旧的躯壳,却已经注入了新的灵 魂。只有调用失败了,它们才会返回 -1,从原程序的调用点接着往下执行。
# 7.2 exec函数族作用图解
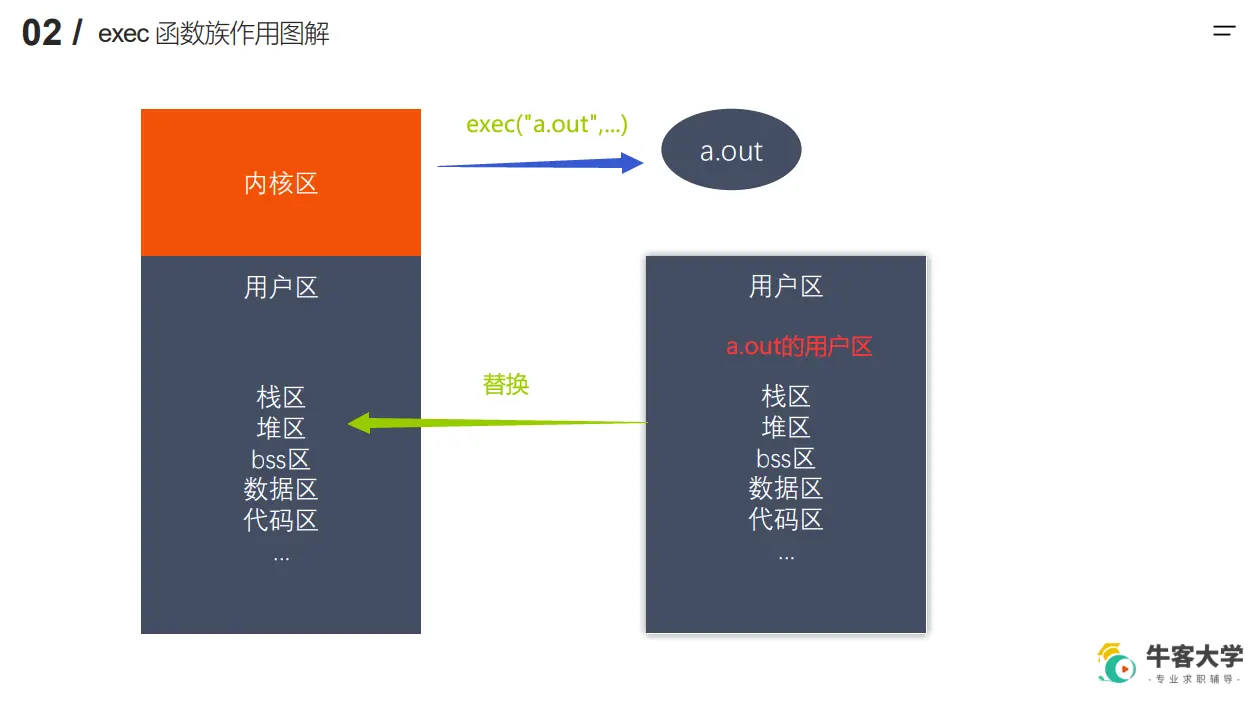
- 当我们使用 exec() 函数执行成功,那么exec所指定的可执行文件所产生的进程的用户区会替换调用 exec()进程的用户区,所以调用程序exec()后面的代码都不会执行,而是从指定可执行文件的main开始执行代码
# 7.3 exec 函数族
- int execl(const char *path, const char arg, .../ (char *) NULL */);
- int execlp(const char *file, const char arg, ... / (char *) NULL */);
- int execle(const char *path, const char arg, .../, (char *) NULL, char * const envp[] */);
- int execv(const char *path, char *const argv[]);
- int execvp(const char *file, char *const argv[]);
- int execvpe(const char *file, char *const argv[], char *const envp[]);
- int execve(const char *filename, char *const argv[], char *const envp[]);
- l(list) 参数地址列表,以空指针结尾
- v(vector) 存有各参数地址的指针数组的地址
- p(path) 按 PATH 环境变量指定的目录搜索可执行文件
- e(environment) 存有环境变量字符串地址的指针数组的地址
# 7.1.1 execl()函数
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
- 参数:
- path:需要指定的执行的文件的路径和名称
a.out /home/nowcoder/a.out 推荐使用绝对路径
- arg:是执行可执行文件所需要的参数列表
第一个参数一般没有什么作用,为了方便,一般写的是执行的程序的名称 (a.out)
从第二个参数开始往后,就是程序执行所需要的参数列表。
参数最后需要以NULL结束 (哨兵)
- 返回值:
只有当调用失败,才有返回值,返回值为 -1,并设置 errno
如果调用成功,没有返回值。
2
3
4
5
6
7
8
9
10
11
12
- 测试代码
//execl.c
#include <unistd.h>
#include <stdio.h>
int main()
{
// 创建一个子进程,在子进程中执行 exec函数族中的函数
pid_t pid = fork();
if (pid > 0)
{
// 父进程
printf("I am parent process,pid : %d\n", getpid());
sleep(1);
}
else if (pid == 0)
{
// 子进程
execl("hello", "hello", NULL);
printf("I am child process, pid = %d\n", getpid());
}
for (int i = 0; i < 3; i++)
{
printf("i = %d,pid = %d\n", i, getpid());
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
//hello.c
#include <stdio.h>
int main()
{
printf("hello,world\n");
return 0;
}
2
3
4
5
6
7
8
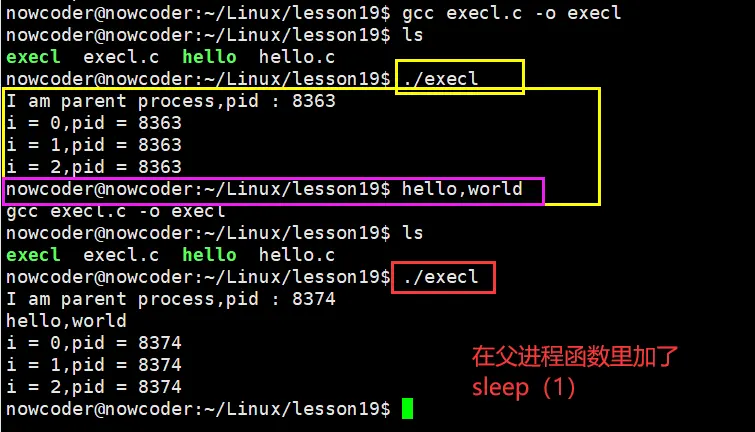
- 🪀:这里会出现他们没有打印在一起的情况,是因为出现了孤儿进程
- 🟥:所以我们在父进程函数里加了 sleep(1) 函数就可以正常打印
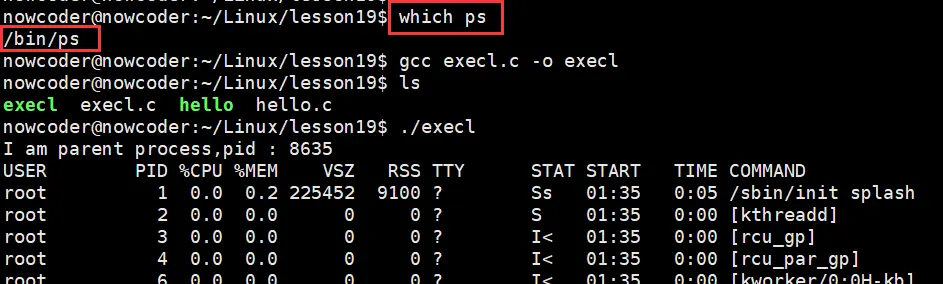
除此以外,execl() 函数还可以执行 系统的shell命令,以
ps aux为例:
先使用
which命令获取 ps 可执行文件的路径再将上面
execl.c代码里的execl("hello", "hello", NULL);改为:
execl("/bin/ps", "ps", "aux", NULL);执行如下:
# 7.1.2 其他exec 族函数
int execl(const char *path, const char *arg, .../* (char *) NULL */);
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
int execle(const char *path, const char *arg, .../*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
int execve(const char *filename, char *const argv[], char *const envp[]);
2
3
4
5
6
7
l(list)参数地址列表,以空指针结尾v(vector)存有各参数地址的指针数组的地址- v 就是让参数以数组的形式传入(所以要先定义好一个列表)
int execv(const char *path, char *const argv[]);
- argv 是需要的参数的一个字符串数组
- 执行案例:
char * argv[]={"ps","aux",NULL};
execv("/bin/ps", argv);
2
3
4
5
p(path)按 PATH 环境变量指定的目录搜索可执行文件
#include <unistd.h>
int execlp(const char *file, const char *arg, ... );
- 会到环境变量中查找指定的可执行文件,如果找到了就执行,找不到就执行不成功
- 参数:
- file:需要可执行文件的文件名
a.out
如果使用用系统的shell命令则直接 ps(不用像execl一样写路径)
- arg:是执行可执行文件所需要的参数列表
第一个参数一般没有什么作用,为了方便,一般写的是执行的程序的名称 (a.out)
从第二个参数开始往后,就是程序执行所需要的参数列表。
参数最后需要以NULL结束 (哨兵)
- 返回值:
只有当调用失败,才有返回值,返回值为 -1,并设置 errno
如果调用成功,没有返回值。
-执行案例:
execlp("ps","ps","aux",NULL);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
e(environment)存有环境变量字符串地址的指针数组的地址e是表示给程序新的环境变量?
int execve(const char *filename, char *const argv[], char *const envp[]);
- 执行案例:
char* envp[]={"/home/nowcoder","/home/bbb","/home/aaa"};
2
3